合约里经常会包含有事件(event关键字),应用通过监听链上指定合约的指定事件,从而得到相应的数据触发相应的处理,也就是不同的系统不再需要链下的交互(api调用等),在这里链扮演了类似持久化的消息队列的角色。在多数场景下,对于链上事件,应用有着可以重复读,可以从指定块开始读,不能丢失事件 等等的需求。应用监听智能合约事件,常见有主动轮询链节点和向链节点订阅推送的方式。当单个应用存在多个实例时,需要在各个实例间协调,避免对同一合约事件的重复处理。同时,当前监听实例一旦下线,对于该合约事件的处理需要由其他实例从当前位置接着消费(应用需要额外设计实现协调机制保证不丢事件不重复消费)。本方案将事件监听和消费协同的功能交给中间件及消息队列等组件。应用无需再额外实现实例间的协调机制,只需要负责从消息队列里消费就可以,保证消息at-least-once消费。一次注册,就可满足单应用多实例甚至多应用的共享。
1 2 3 4 5 6 7 8 9 10 monitor |_ nodes |_ active (ephemeral节点,记录active monitor的信息,如ip,端口等) |_ events(永久节点) |_ foo(该节点记录对应的contract address,abi, event name等信息,唯一确定链上合约事件) |_ latsBlock(该事件最近已消费的区块高度) |_ topic(对应的kafka topic名) |_ bar |_ lastBlock |_ topic
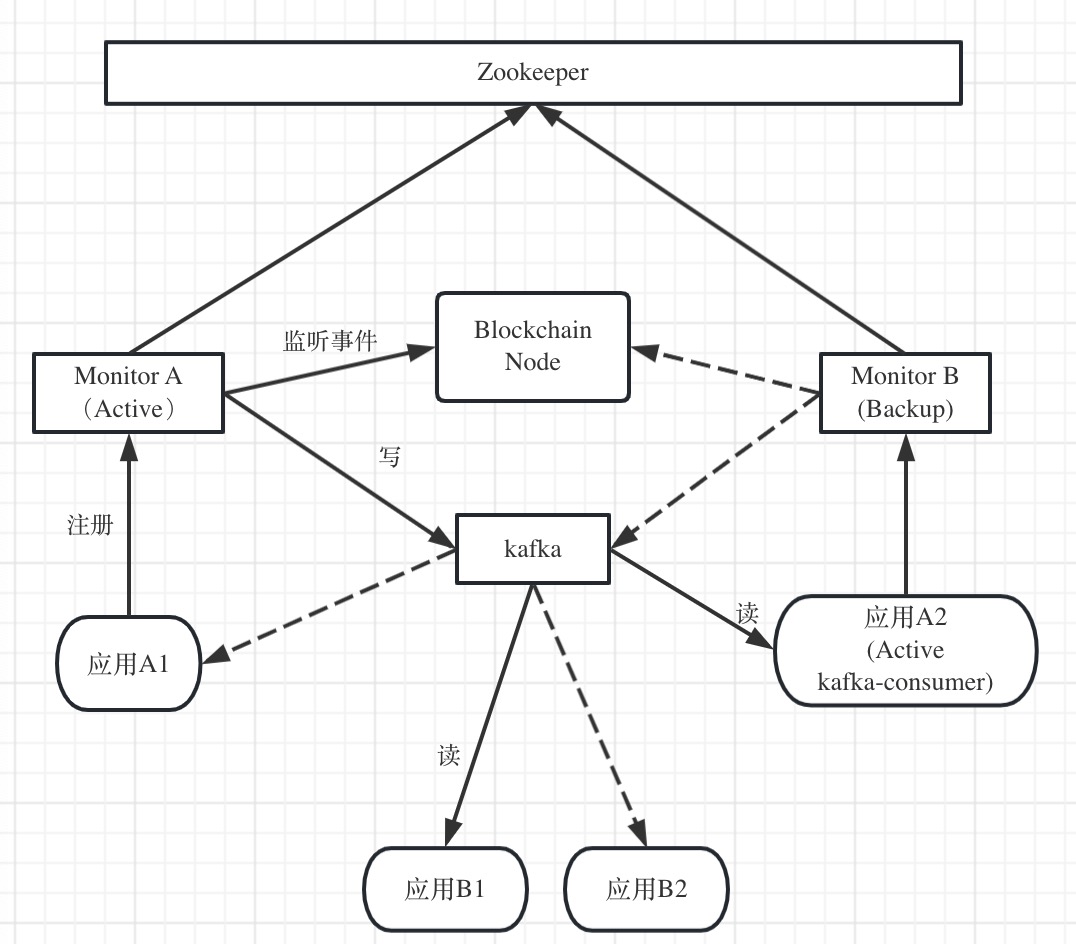
各个monitor向zk的monitor/nodes/active节点注册选主,保证只有一个monitor是active。该active monitor负责获取链上合约事件,写入kafka。各个非active的monitor监听该zk节点,如果发现active monitor离线(zk节点消失),则尝试注册,注册成功者成为新的active。有时候active monitor可能会有丢失心跳包等假死的现象,恢复连接后,需要重新注册,判断是否自己是否是active(这部分可以参考常用的zk抢主方案)。
应用通过monitor(主从皆可)创建event节点,即创建特定链事件的监听任务。monitor需要判断zk里是否已经有该event,如果有,则返回已存在的错误码。如果没有,则在events节点下创建以该事件命名的节点,写入对应的链事件信息。如果应用不再需要监听该事件,可以删除监听任务,也即是从zk上删除该节点。(暂停/重新启动的功能机制较复杂,不展开详述)。从应用的角度,只需要注册一次,应用以及monitor重启后都无需重新注册。
active monitor需要监听events目录下节点的增删,对应的启动/停止消费链上合约事件。针对每个事件当前已消费的最新区块高度写到该事件lastBlock节点下。monitor每次消费完成之后需要更新该lastBlock值。monitor主从切换或者全局重启后,active monitor需要扫描events目录下的所有节点记录从各个事件的lastBlock处接着消费。
monitor采用pull的机制使用getLogs接口向链获取日志,(from, to)分别是(lastBlock+1, currentBlockHeight),发送到kafka后再更新zk的值。异常情况下(发送kafka成功,但是更新zk失败)可能会重复推送。在应用本身负责消息的去重处理。
对于某些事件需要按照上链时间的顺序处理的,需要设置kafka里的分区数为1,否则会在应用端乱序处理。
此方案所有链上合约事件都是由单个active monitor处理,如果监听事件比较多的时候,压力过大容易成为瓶颈。不过,大多数情况下,由于monitor监听处理的速度要远远快于区块链出块的速度,大多数事件的lastBlock是相近的,monitor可以聚合获取区块事件,然后再区分不同的事件相应处理,不需要单独对每个事件向链节点单独获取。新创建的监听事件若指定从历史的fromBlock开始处理,可以单独维护消费任务线程,等追上主流消费进度后再merge监听任务。
1 2 3 4 5 6 7 8 9 10 11 12 13 monitor |_ nodes |_ 0(顺序ephemeral节点,存放节点信息等,例如${ip1:port1}) |_ 1(${ip2:port2}) |_ events(永久节点) |_ foo |_ active (ephemeral节点,记录active monitor的信息,如ip,端口等) |_ lastBlock |_ topic |_ bar |_ active |_ lastBlock |_ topic
每个事件都有各自的active monitor,分散处理压力。
应用通过monitor创建监听任务时,该monitor同时把自己注册成该event的active实例。各个monitor监听events节点下的所有event的active节点(例如foo/active, bar/active),当active节点消失后(该monitor宕机或者下线),其他monitor抢主,新的active monitor接着消费。
在各个事件的active monitor分散的情况下,区块需要被每个monitor读取解析以获取各自负责的合约事件,造成不必要的重复读取(如果链本身有针对事件的bloom过滤器可减轻此影响)。
极端情况下,例如所有应用恰好都通过同一个monitor创建监听任务,最终退化成前述的全局唯一active monitor。一种改进方式是,创建监听任务时monitor只负责创建event节点,但是并不把自己注册为active。所有的monitor需要监听events和nodes里所有节点,如果有新增/删除事件节点,或者节点动态加入/退出,需要执行rebalance重新分配(可以通过一个协调者来分配)。这个rebalance机制的可靠性实现会相当复杂。