Dunbar项目是BIS新加坡创新中心,the Reserve Bank of Australia (RBA), the Bank Negara Malaysia (BNM), the Monetary Authority of Singapore (MAS) and the South African Reserve Bank (SARB) 在2021年合作实验项目,意在研究批发型CBDC在跨境结算中发挥的作用,并在同年11月公开发布研究报告。具体参见BIS的项目介绍Project Dunbar: international settlements using multi-CBDCs。
Dunbar项目的探讨了跨境支付,FX等场景,与其他的跨境批发CBDC项目(例如Jura, mBridge等)关注点基本一致。同时,报告中也有其独特的有意思的一些设计。
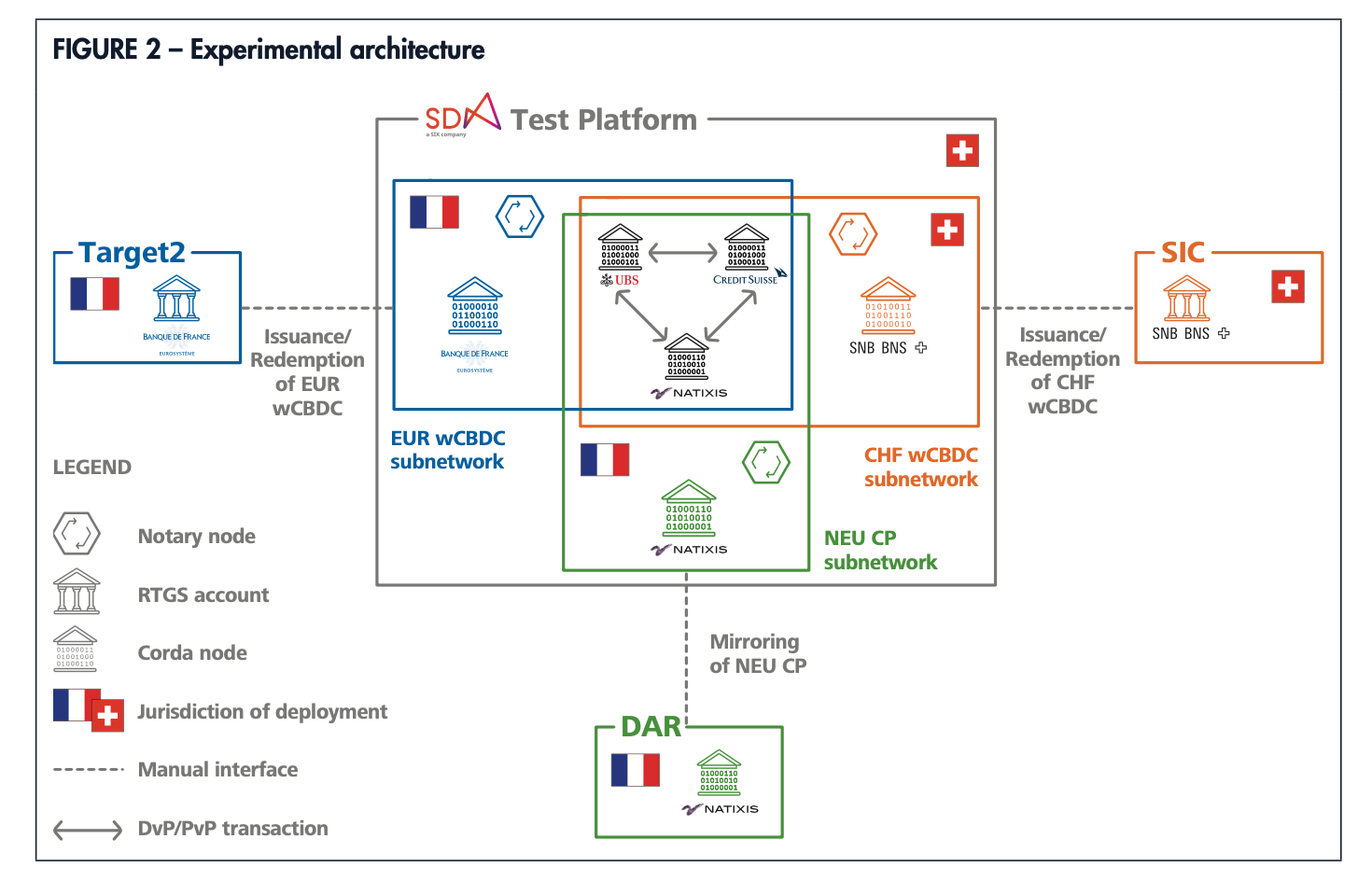
1.项目的组织。项目拆分为设计和技术开发两个工作组,职责分离;设计工作组着眼于业务需求,包括交易流程设计,合规监管,治理模式等;而作为试验性的项目,技术开发采用了Corda(账本隔离,只能看到己方相关交易信息,不存在全局一本帐)和Quorum(类企业级以太坊,以dApp智能合约的方式按币种逻辑隔离,用Tessera方案解决隐私)两种常用的DLT技术路线并行开发原型,探讨不同的技术路线对于需求的满足度。整个过程采用敏捷开发的方式,拆分迭代,适合这种多团队间的合作。
图1 拓扑
2.角色的划分。虽然项目的目的是为了解决当前跨境支付中依赖中介,导致交易链路长,耗时多,费用高等痛点,但考虑到实际中由于参与银行的规模,从属等,也试图最大程度利用代理银行的优势。项目将参与各方划分成以下多个角色职责,主要关注银行的划分。特许银行(一般是规模大实力强的本地银行)承担最多的职能,包括与传统支付系统互联,执行CBDC交易,登入其他非特许银行/非本地银行,对其进行AML审查等。相比其他项目里只考虑了直参,dunbar在角色设计考虑的更多,并且也赋予此类特许银行更高的权限,参与到整个项目的治理中,而并非仅仅只是规则遵守者。
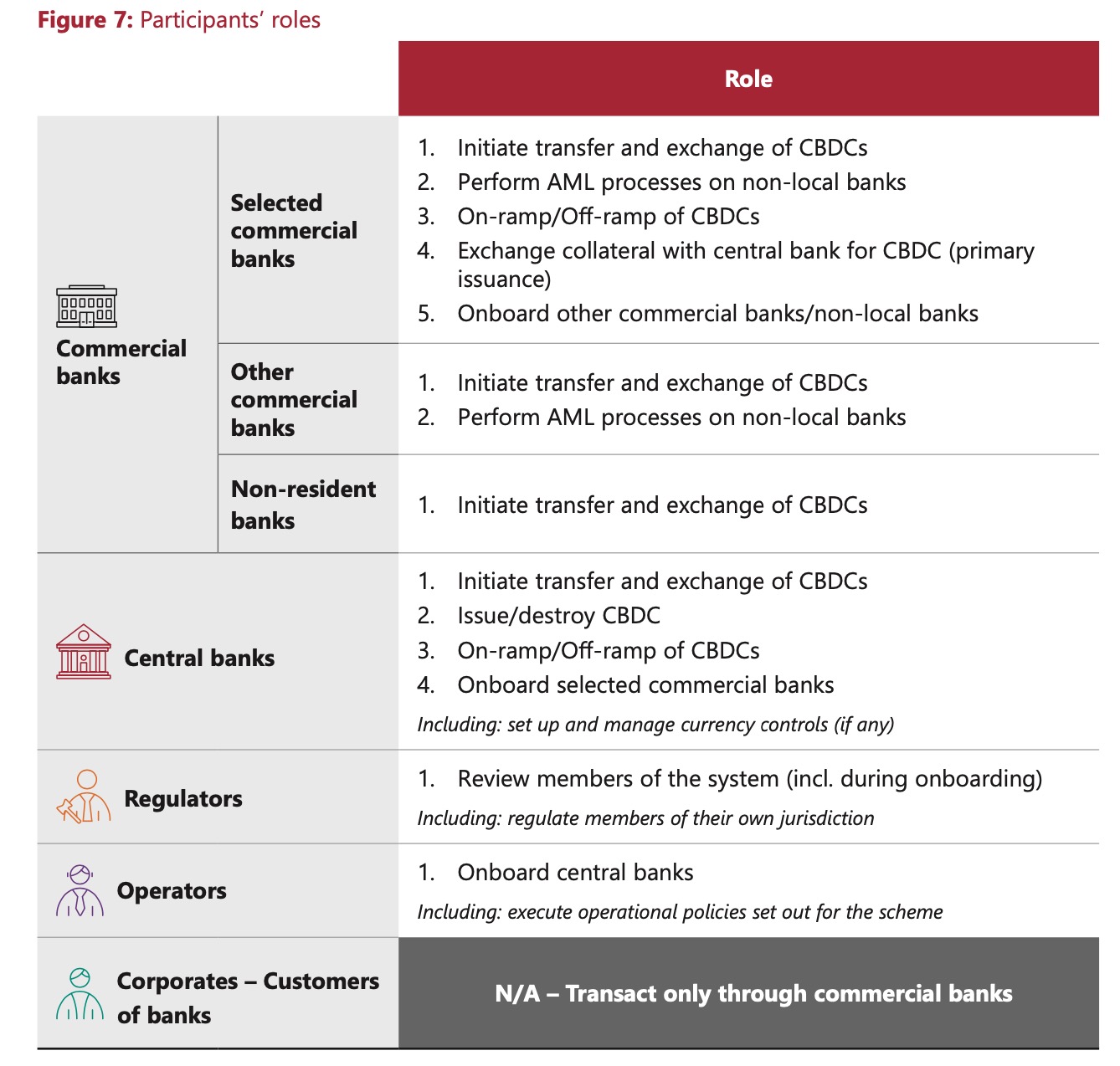
图2 参与者角色
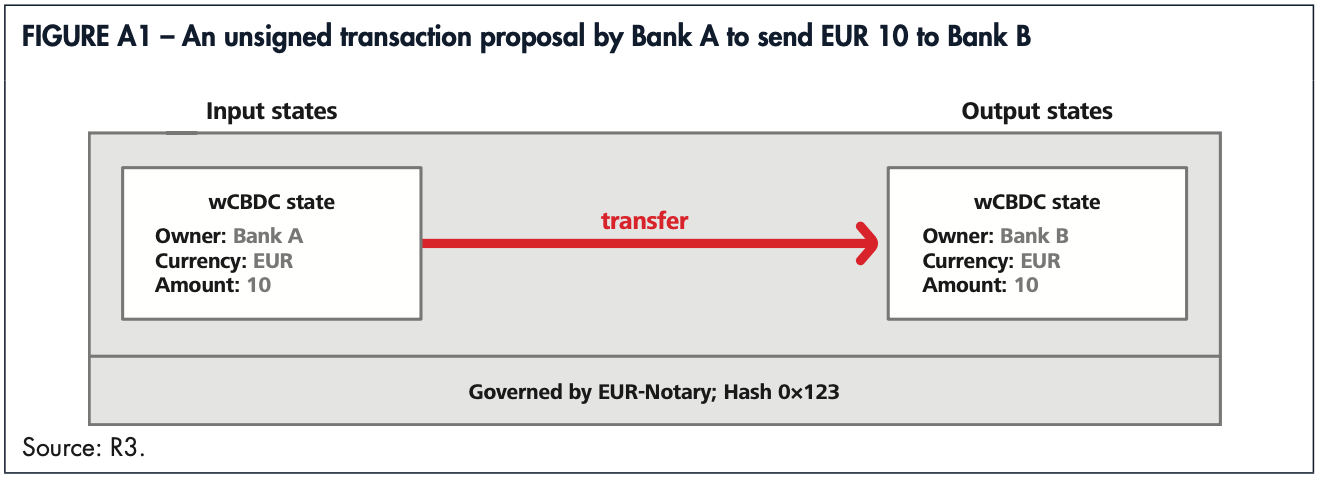
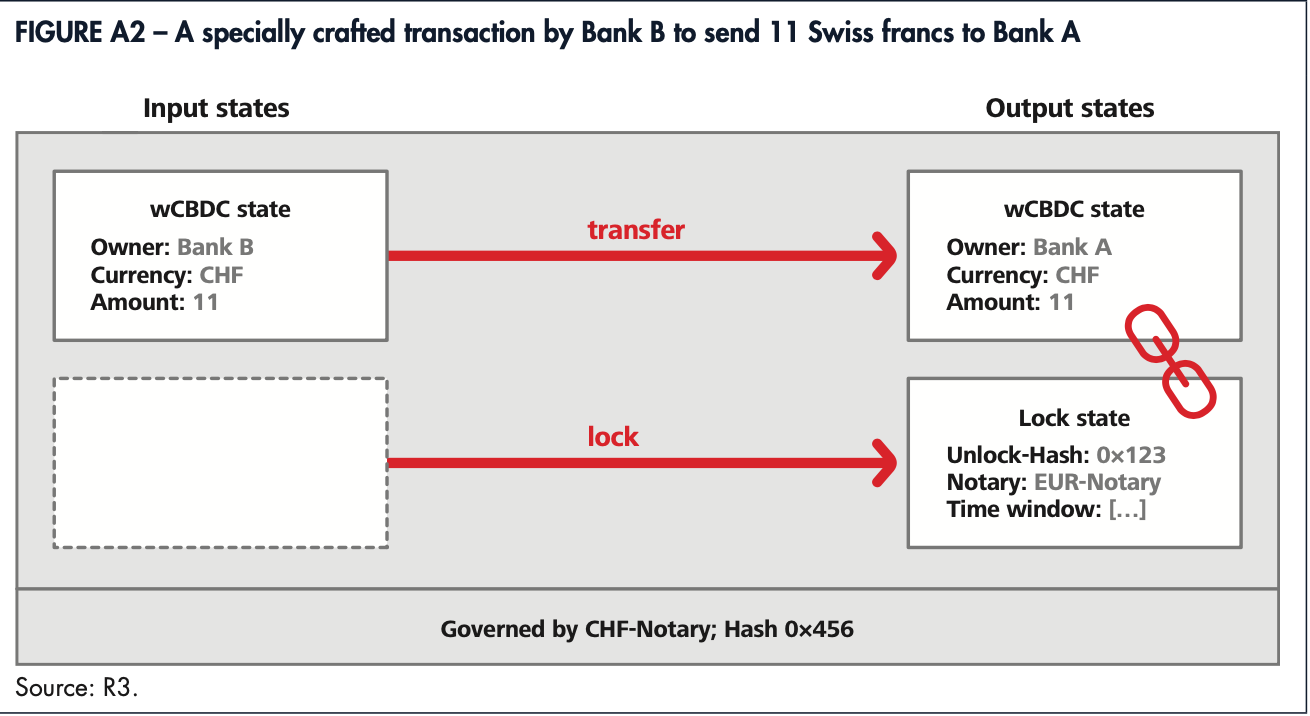
由于各参与方(主要是商业银行)的职责和参与度不同,跨境支付场景下的流程简化如下。其中,只有收付双方的Sponsor bank都执行完AML等风控措施通过后,批准执行交易,此交易才会在智能合约里执行。
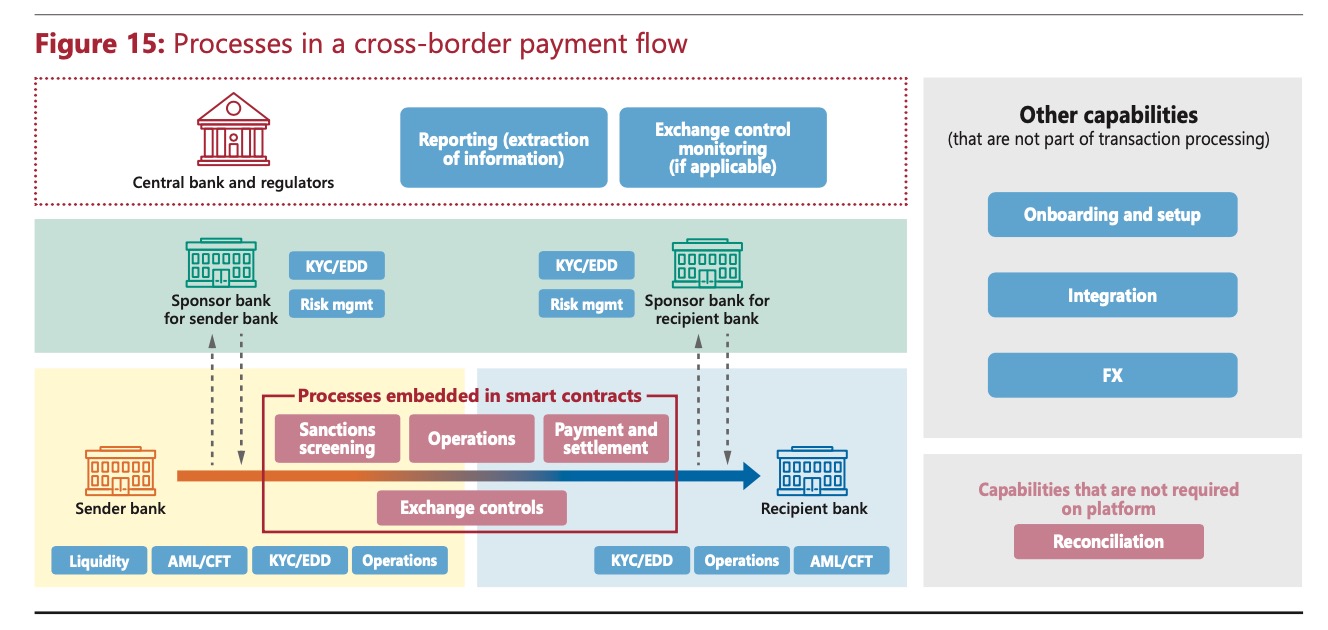
图3 跨境支付流程
对于FX,则对比了多个模型,其中考虑到AMM(Automated market- making)这种在加密资产业界常用的方式。具体的本期没有过多的展开和实现,留到将来的研究。
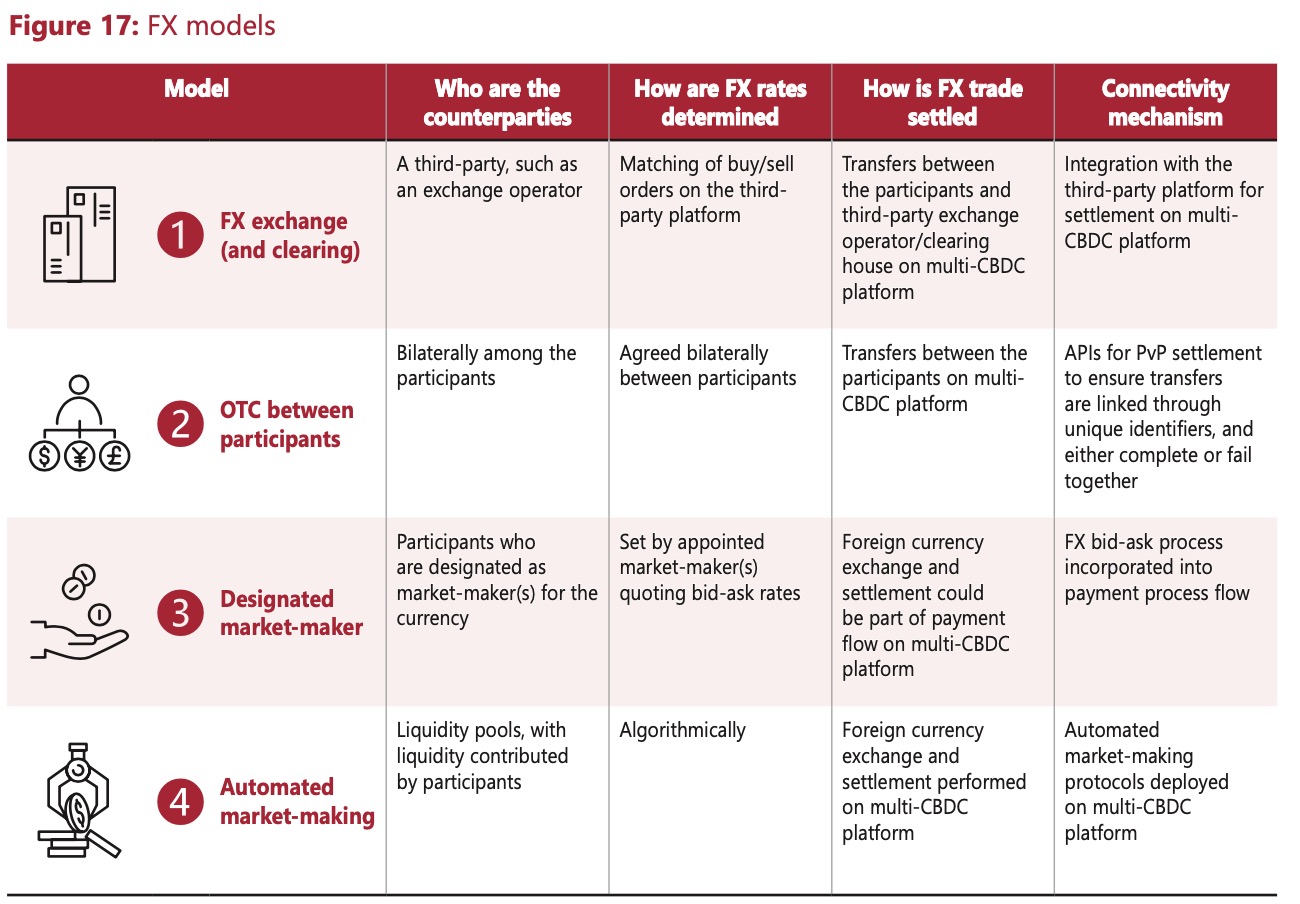
图4 FX模型
3.未来多平台互联。报告最后预测了将来的multi-CBDC平台会是多个地区性平台互联组成的一个通用平台,而不是全球唯一的。下一步的工作是保证这些平台的互联互通。个人深以为然,在当前BIS的牵头下已经存在了多个类似项目的持续试验和演进中,在技术上是可行的,在治理方面,各平台方有各自协商一致的治理方式,合规等,比起传统swift仅仅只是消息系统,当前的mCBDC平台赋予了更多的能力,及时结算,这个与各辖区的法令和风控制度等也有很大的关联,一个全球参与建设的平台从协商组织上难度也很大,最后很容易沦为寡头政治的金融工具。因此,当前BIS牵头的多个mCBDC平台在齐头并进,并且有更多的项目也在新增研发中。同一个实体同时参加不同的项目,不同的区域性性平台,也是会出现的。